Articles from the wikipedia processing thread:
-
1 - Understanding the Wikipedia Dump
- 2 - Processing the Wikipedia Dump done
1 - Understanding the Wikipedia Dump done
As a part of my work on SearchOnMath, I’ve always been in trying to find better ways to retrieve and process data, making sure it’s in good shape for our powerful mathematical search engine. Wikipedia has always been a problem in such workflow, since the pages are written in a markup language called Wikitext, which is not easy to understand or apply operations to.
Here I will briefly describe how the data is structured inside the dump - which is a humongous XML file - and try to make sense of such structure while not going full clichê and only displaying the XML schema. In the end I’ll give an example of how I visualize the document as a relational model, and on following posts I’ll describe how I wrote a processor for this XML to fill the given relational model - parallelizing bz2 streams, hopefully. Let’s go and understand this data first.
First steps
To store the clean needed data, we first need to somehow ingest it from the source, and the source is the Wikimedia database backup dump. Those backup dumps come in the form of big XML files compressed into big bz2 multistream archives. The provided XML schema is a good way of understanding the whole specification, sometimes looking at the data is very important to understand what we have and what we need from this immense amount of information. To make things easier, I’ll try to refer to such XML documents in a object-oriented manner and I swear it’ll be much easier than referring to all the different types of “complex elements” that might be inside of this XML document.
I would say this XML file structure is made by only two main object types: the siteinfo object and the page object, each one having multiple associated objects, fields and attributes which we will discover one by one - and focus on the most important ones.
The siteinfo object
This structure’s main part comprises informations about the source of the dump, such as the link to the main page of the wiki and the sitename. Below is a real example:
<siteinfo>
<sitename>Wikipedia</sitename>
<dbname>enwiki</dbname>
<base>https://en.wikipedia.org/wiki/Main_Page</base>
<generator>MediaWiki 1.38.0-wmf.22</generator>
<case>first-letter</case>
<namespaces>
...
</namespaces>
</siteinfo>
We see that the siteinfo object is composed by:
dbname: an indicator of this Wikipedia instance, it might work as an idsitename: the name of the Wikipedia, well formatted, that can be displayedbase: the link to the base page of this Wikipedia, the main onegenerator: information about the MediaWiki software used by this instance of the Wikipedia when such dump was generatedcase: I believe this is strictly correlated to the sitename formatting, only uppercasing the ‘first-letter’
We can see that the first field is the sitename which is referring to the name of the site where this dump came from - I’ll not dive deeper to explain the whole usage of the MediaWiki software to build what is now the Wikipedia website here, so I’ll let you discover it all if you want to. Then the dbname comes, and I like to think of this dbname as a discriminator to be used inside of the Wikipedia dumps. Fir example, we might have the “enwiki” for the English variation, the “dewiki” for the German variation, and so on. The base attribute indicated the base page to facilitate the access and the case is a formatting thing that should not be useful for us right now.
The namespaces is a child object of the siteinfo which allow us to search for information in the right place. When looking at the explanation for each namespace, we might understand that if we only need to analyse articles, we might only retrieve from this dump pages associated with the namespace 0, but if we want to analyse what users are discussing about changes in a certain page, we might look for pages associated with the namespace 1. The namespaces object is formatted as:
<namespaces>
<namespace key="-2" case="first-letter">Media</namespace>
<namespace key="-1" case="first-letter">Special</namespace>
<namespace key="0" case="first-letter" />
<namespace key="1" case="first-letter">Talk</namespace>
<namespace key="2" case="first-letter">User</namespace>
...
<namespace key="2300" case="first-letter">Gadget</namespace>
<namespace key="2301" case="first-letter">Gadget talk</namespace>
<namespace key="2302" case="case-sensitive">Gadget definition</namespace>
<namespace key="2303" case="case-sensitive">Gadget definition talk</namespace>
</namespaces>
Each namespace has a few important attributes:
key: is a namespace identifier used to make the search and link of the namespaces easiercase: I believe this is strictly correlated to the displayable name of each namespace
Exactly as it should from the namespaces explanation link we’ve seen before, right? The content of each namespace attribute is just a displayable friendly name.
And this is all we have on this siteinfo element that should be important for us to understand. This is a very important piece of information too have, and we’ll see it soon. Let’s check the page object’s structure.
The page object
Now things get a bit more exciting. This page object is where all the information of a single page is stored inside this big XML file, and since we have millions of pages inside the Wikipedia, we have millions of such objects inside the XML dump. Each page object is given as:
<page>
<title>AccessibleComputing</title>
<ns>0</ns>
<id>10</id>
<redirect title="Computer accessibility" />
<revision>
...
<contributor>
...
</contributor>
</revision>
</page>
We see that the page object is composed by:
id: a unique identifier for this page inside of this Wikipedia instancetitle: the title of the page, well formatted, that might be displayedns: this is the namespace of the pageredirect: when this page is just a redirect page, thisredirectfield appears with thetitleattribute containing the name of the page it should redirect to
The redirect thing is kinda common to happen inside the Wikipedia, hundreds of thousands of pages are only redirect pages. For example, try to access AccessibleComputing page and see how it redirects you to the Computer accessibility page. Also, the text for such pages are only a directive indicating it is a redirect page and nothing else - more on that soon.
Then, for the child objects that compose a page, we have the revision object which is very important. The revision fields are as follows:
<revision>
<id>1002250816</id>
<parentid>854851586</parentid>
<timestamp>2021-01-23T15:15:01Z</timestamp>
<contributor>
...
</contributor>
<comment>shel</comment>
<model>wikitext</model>
<format>text/x-wiki</format>
<text bytes="111" xml:space="preserve">#REDIRECT [[Computer accessibility]]
{{rcat shell|
{{R from move}}
{{R from CamelCase}}
{{R unprintworthy}}
}}
</text>
<sha1>kmysdltgexdwkv2xsml3j44jb56dxvn</sha1>
</revision>
So the revision object is composed by:
id: a unique identifier of this revision inside of this Wikipedia instanceparentid: the id of this revision’s parent, that is, the id of the revision that comes before this one for this same pagetimestamp: the time which this revision was generatedcomment: some comment added by the contributor who sent this revisionmodel: the model in which this text is formattedformat: seems like something that could be used in aContent-Typeheader internallytext: the text of this revision, our gold minesha1: hash of the text generated by the SHA-1 algorithm
See what I’ve said about the redirect page’s text? Nothing else but a few lines always starting with with “#REDIRECT”, followed by some strange template things or wathever, and that’s it - from a processing point of view, completely disposable.
At this point we should know that Wikipedia is built by contributors, and all the changes made by a contributor to a certain page, or the very first addition of text to one of them, gives life to a new so-called revision.
The contributor child object, which is the object that identifies the user who made this change to the page with the given revision, is given as below:
<contributor>
<username>Elli</username>
<id>20842734</id>
</contributor>
And the explanation of the contributor fields are:
id: a unique identifier of this contributor inside of this Wikipedia instanceusername: a displayable/more user friendly username
And that’s it. Just like this, it’s the whole document specification we need to know and even some information that in fact we don’t need to know to process this data.
A relational model example
When I see all those objects with fields related to each other, I like to imagine it as relational data and build a relational structure in my head. So I go around and think… “if this page has this id, and this revision is related to this page with this other id, and this contributor wrote this revision with this other id… how can I quickly navigate such structure by connecting those ids?” - and all of a sudden you have your whole relational model done.
Below is how my relational structure ended up thinking of:
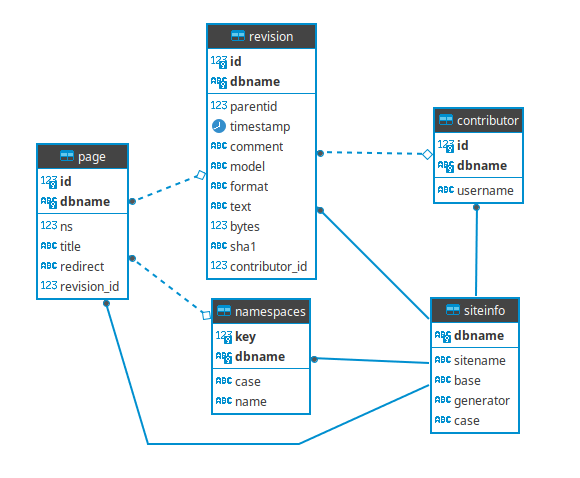
You might be finding it very strange that every single table has a composite primary key… well, let me explain. All those ids are only unique for each available Wikipedia around there, so the “enwiki” has its pool of ids, and then the “dewiki” also has its own pool of ids. So, to be able to use this single database and have all the data available for a multi-language type of search engine - for example - I might use the siteinfo dbname field as a discriminator - which works perfectly.
It’s minimum, it doesn’t have extra tables to connect one-to-many relationships in the case of contributors because I don’t need it to, and it actually solves all of my problems when processing this data.
Processing the XML dump
I’m going to start my next post from this relational structure diagram, explaining how you can build a fairly fast (parallel per-stream, at least on paper) processor for this XML dump (in Scala, or Java - preferably), and the ins and outs of reading a XML multistream file using the Apache Commons Compress.